1
 U-net架构
U-net架构
2
微调在新数据上重新训练现有模型,以改变它们生成的内容。 引导使用现有模型,在推理时引导生成过程,以获得额外的控制。
引导
在推理时,不仅往原图的方向拉:x = scheduler.step(noise_pred, t, x).prev_sample。
也往新限制的方向拉(梯度下降):x -= cond_grad,cond_grad是新限制的loss值对x的梯度。新限制的loss值可以是例子中的color_loss(images, target_color),或者clip_loss(image, text_features)。
向模型添加条件信息
输入变量(作为1维)拼接条件嵌入(k维),将条件嵌入的k维作为UNet新增的k个输入通道
# x is (bs, 1, 28, 28) and cond_embedding is (bs, 4, 28, 28)
net_input = torch.cat((x, cond_embedding), 1) # (bs, 5, 28, 28)3
3.2
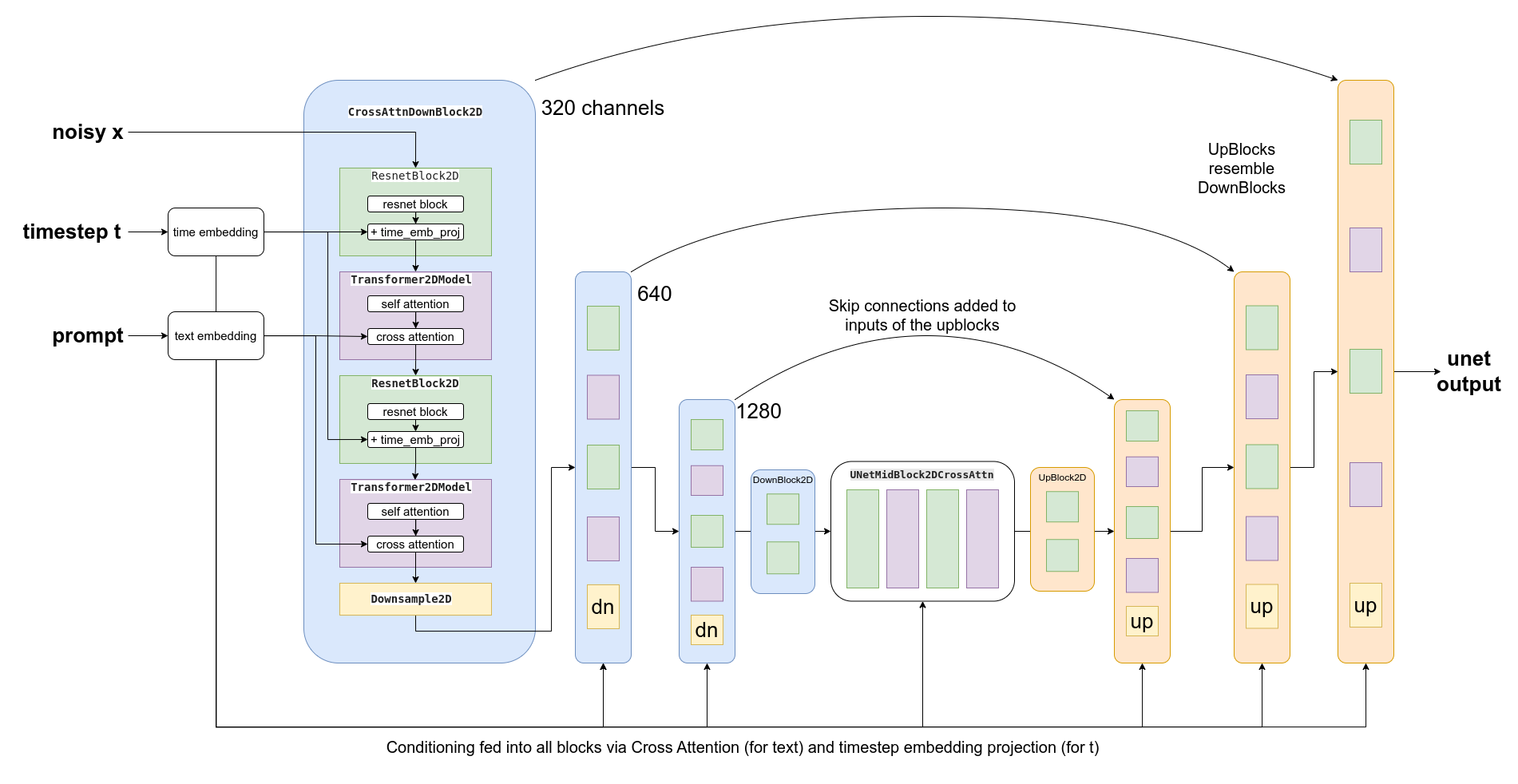
潜在扩散模型:将扩散应用于VAE的潜在表示
文本token化 — CLIP-based pre-trained transformer —> 文本的embedding —> AttnDownBlock2D或AttnUpBlock2D的CrossAttention模块
CFG(Classifier-Free Guidance,无分类引导): 在训练过程中,保持文本条件为空,迫使模型学会在没有任何文本信息的情况下去除噪声(无条件生成)。然后在推理时,进行两次独立的预测:一次使用文本提示作为条件,一次不使用。然后可以使用这两种预测之间的差异来创建一个最终的综合预测,根据某个缩放因子(引导比例)进一步推动结果向文本条件预测指示的方向发展。
其他类型的条件化: 超分辨率,Inpainting,Depth-to-Image
3.2