1
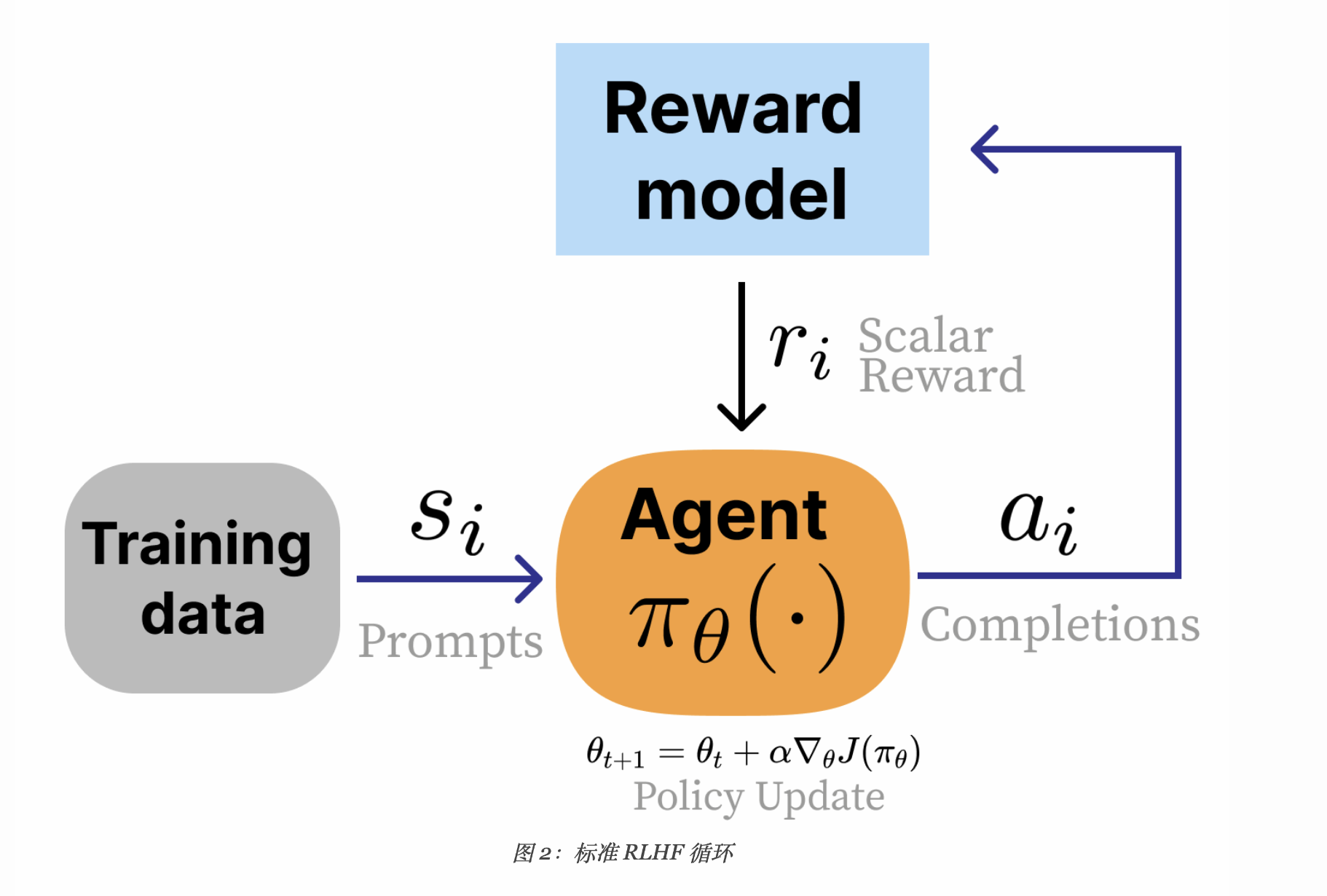
RLHF 的基本流程涉及三个步骤。首先,需要训练一个能够回答用户问题的语言模型。其次,需要收集人类偏好的数据,用于训练人类偏好的奖励模型。最后,可以选择一个 RL 优化器,通过采样生成并根据奖励模型进行评分来优化语言模型。
后训练可以总结为使用三种优化方法:
- 指令 / 监督微调 (SFT)
- 偏好微调(PreFT),和
- 强化微调 (RFT)。
4
从标准的 RL 设置到 RLHF,有多处核心更改:
- 从奖励函数切换到奖励模型。在 RLHF 中,使用一个学习到的人类偏好模型(如
或其他分类模型)代替环境奖励函数。 - 不存在状态转换。在 RLHF 中,初始状态是采样自训练集的prompt,“动作”是对此prompt的completion。在标准实践中,此动作不会影响下一个状态,仅由奖励模型评分。
- 对整个响应的奖励。RLHF 对奖励的归因是基于一系列动作,这些动作由多个生成的 token 组成,而不在更细的粒度上进行。
给定问题是单轮的,优化可以不使用时间范围和折扣因子(以及奖励模型)重新编写:
RLHF 是从一个强大的基模型实现的,这引出了需要控制优化不要偏离初始策略太远的需求。为了在微调阶段取得成功,RLHF 技术采用了多种类型的正则化来控制优化。优化函数中最常见的变化是添加一个距离惩罚,该惩罚基于当前 RLHF 策略与优化初始点之间的差异:
7
有两种流行的表达方式用于训练奖励模型,它们是数值等价的。经典的实现是从 Bradley-Terry 偏好模型派生而来的。一个 Bradley-Terry 偏好模型衡量的是从同一分布中抽取的两个事件 i 和 j 进行成对比较时满足关系 i>j 的概率。
要训练一个奖励模型,我们要指定一个满足上述关系的loss函数。首先需要一个将语言模型转换为标量值输出的打分模型
然后,通过对模型参数求梯度,我们可以得到用于训练奖励模型的损失函数。
第一种形式,
第二种形式:
推导: 由(2)式得(3)式,
, 由(3)式得(4)式, 代入
代码示例:
import torch.nn as nn
rewards_chosen = model(**inputs_chosen) # 正样本
rewards_rejected = model(**inputs_rejected) # 负样本
loss = -nn.functional.logsigmoid(rewards_chosen - rewards_rejected).mean()在训练奖励模型时,最常见的做法是只训练 1 个 epoch 以避免过拟合。
8
在整个 RLHF 优化过程中,使用了许多正则化步骤以防止奖励模型过度优化。
在使用 RLHF 框架并结合奖励模型时,通用公式如下:
参考实现如下:
其中KL散度定义:
在 RLHF 中,感兴趣的两个分布是新模型的分布
在实践中,KL距离的实现通常会被近似化,KL的求和可转换为直接从分布
10
拒绝采样(Rejection Sampling)通过收集新的候选指令,根据训练好的奖励模型进行过滤,然后仅在最佳的completions上微调原始模型。
11 策略梯度算法
目标是估计精确的梯度
:轨迹的总奖励 :奖励后续动作 :前一个公式的基线版本 :动作-价值函数 :优势函数 :TD残差 基线是用于减少策略更新方差的值
PPO: Proximal Policy Optimization
REINFORCE名称可能是回文缩略词:REward Increment = Nonnegative Factor X Offset Reinforcement X Characteristic Eligibility
GRPO: Group Relative Policy Optimization GRPO