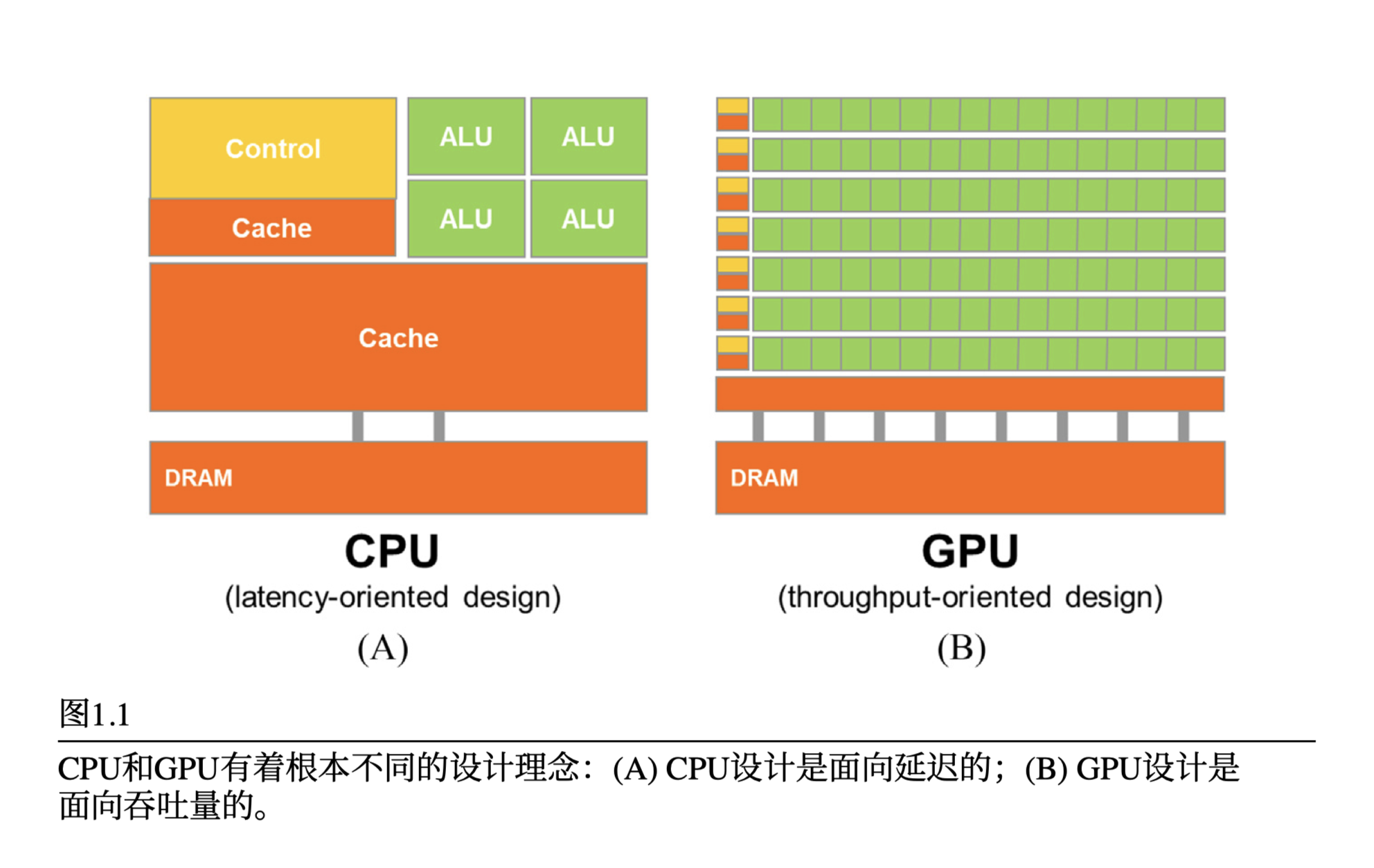
1
2
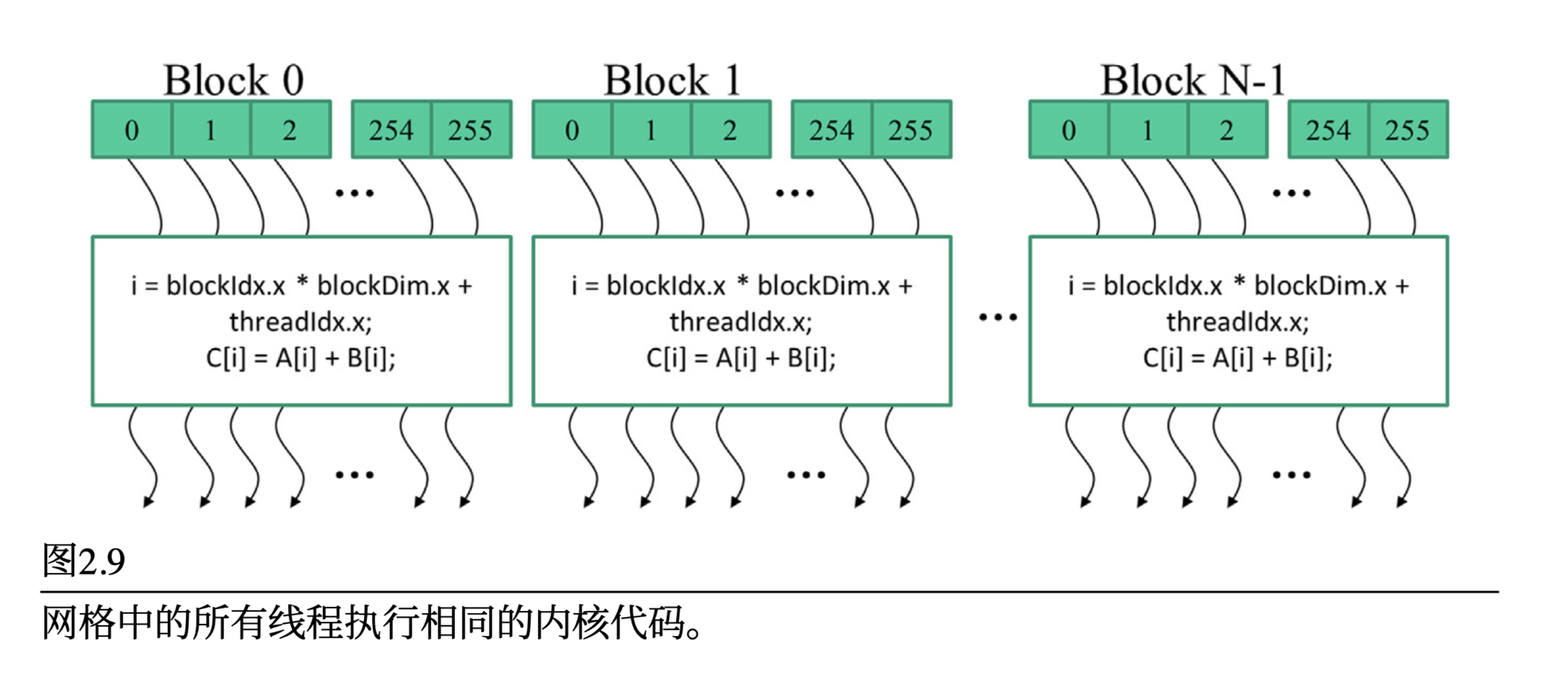
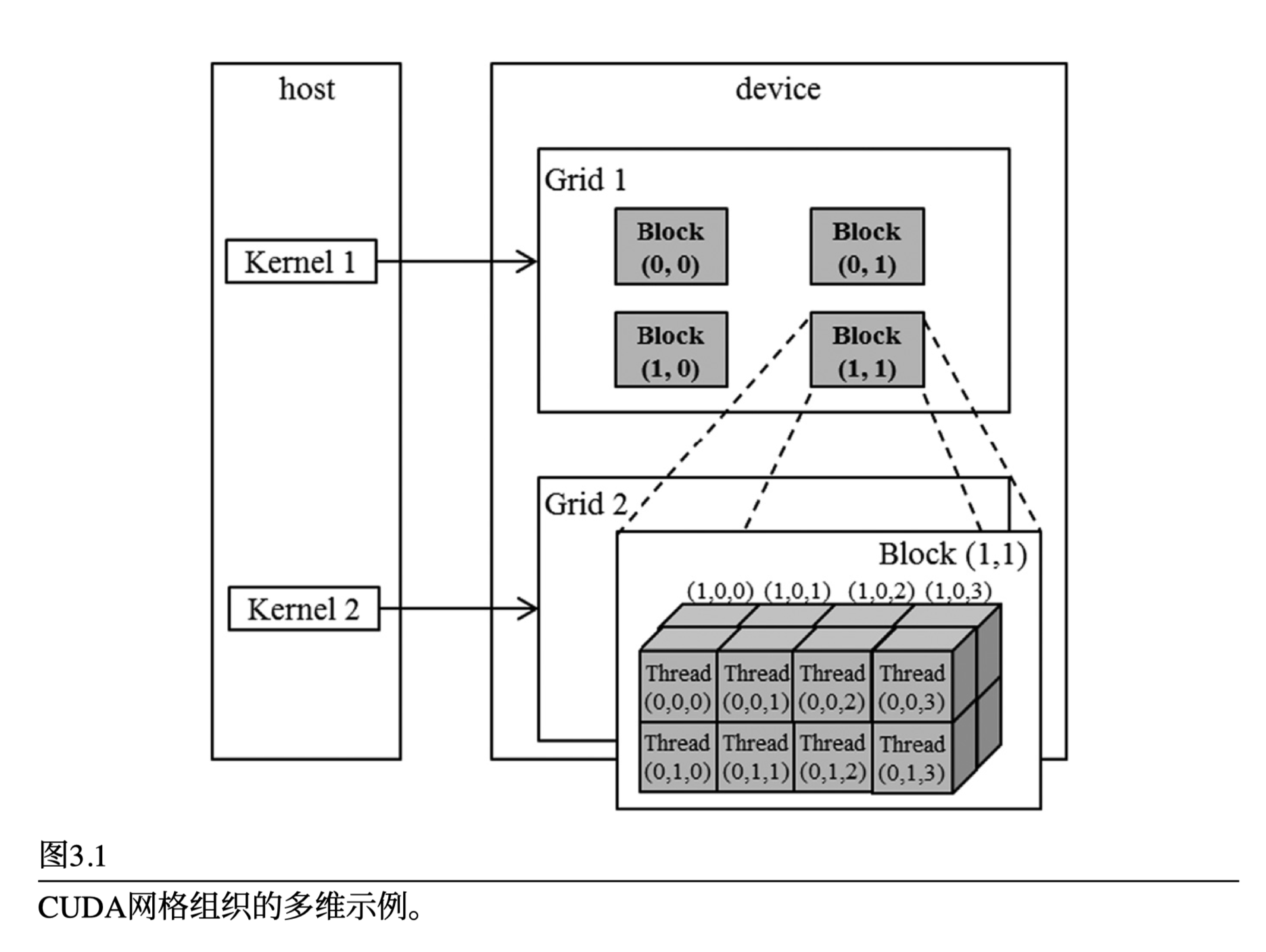
 CUDA程序调用内核函数启动并行执行,这会启动一个线程网格
CUDA程序调用内核函数启动并行执行,这会启动一个线程网格
// Compute vector sum C = A + B
// Each thread performs one pair-wise addition
__global__
void vecAddKernel(float* A, float* B, float* C, int n) {
int i = threadIdx.x + blockDim.x * blockIdx.x;
if (i < n) {
C[i] = A[i] + B[i];
}
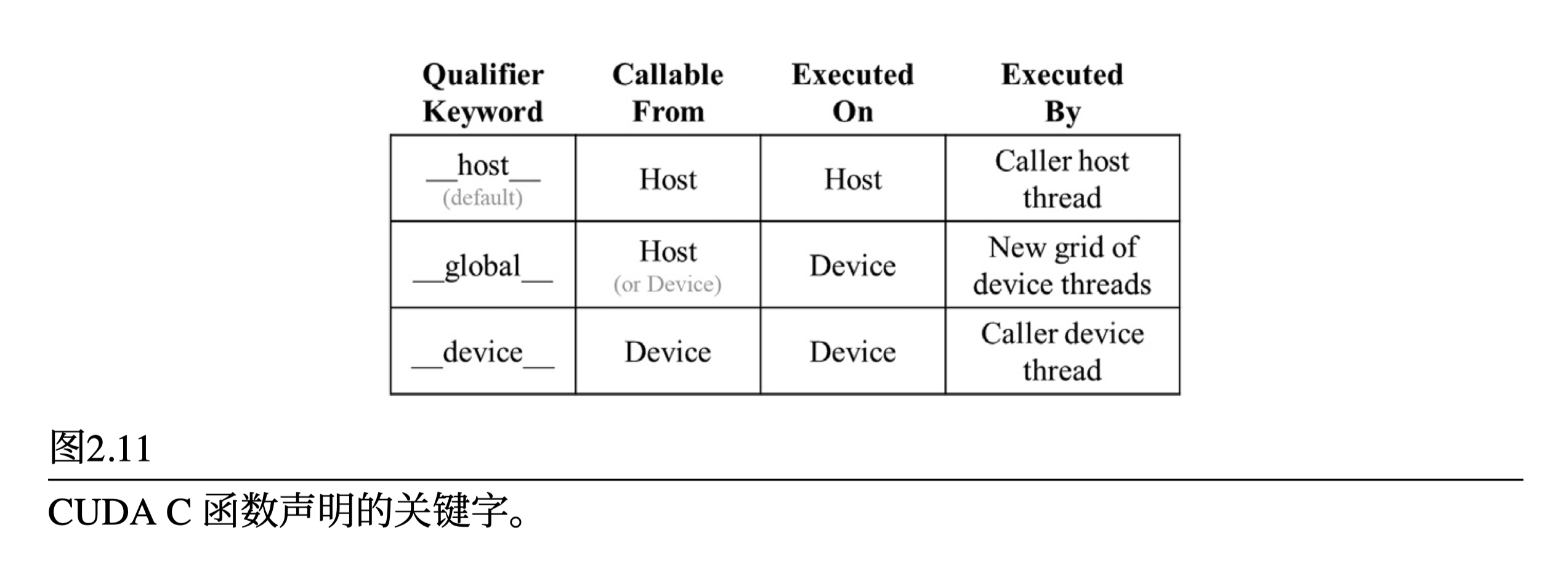
}用__global__声明为核函数
int vectAdd(float* A, float* B, float* C, int n) {
// A_d, B_d, C_d allocations and copies omitted
...
// Launch ceil(n/256) blocks of 256 threads each
vecAddKernel<<<ceil(n/256.0), 256>>>(A_d, B_d, C_d, n);
}调用核函数

4
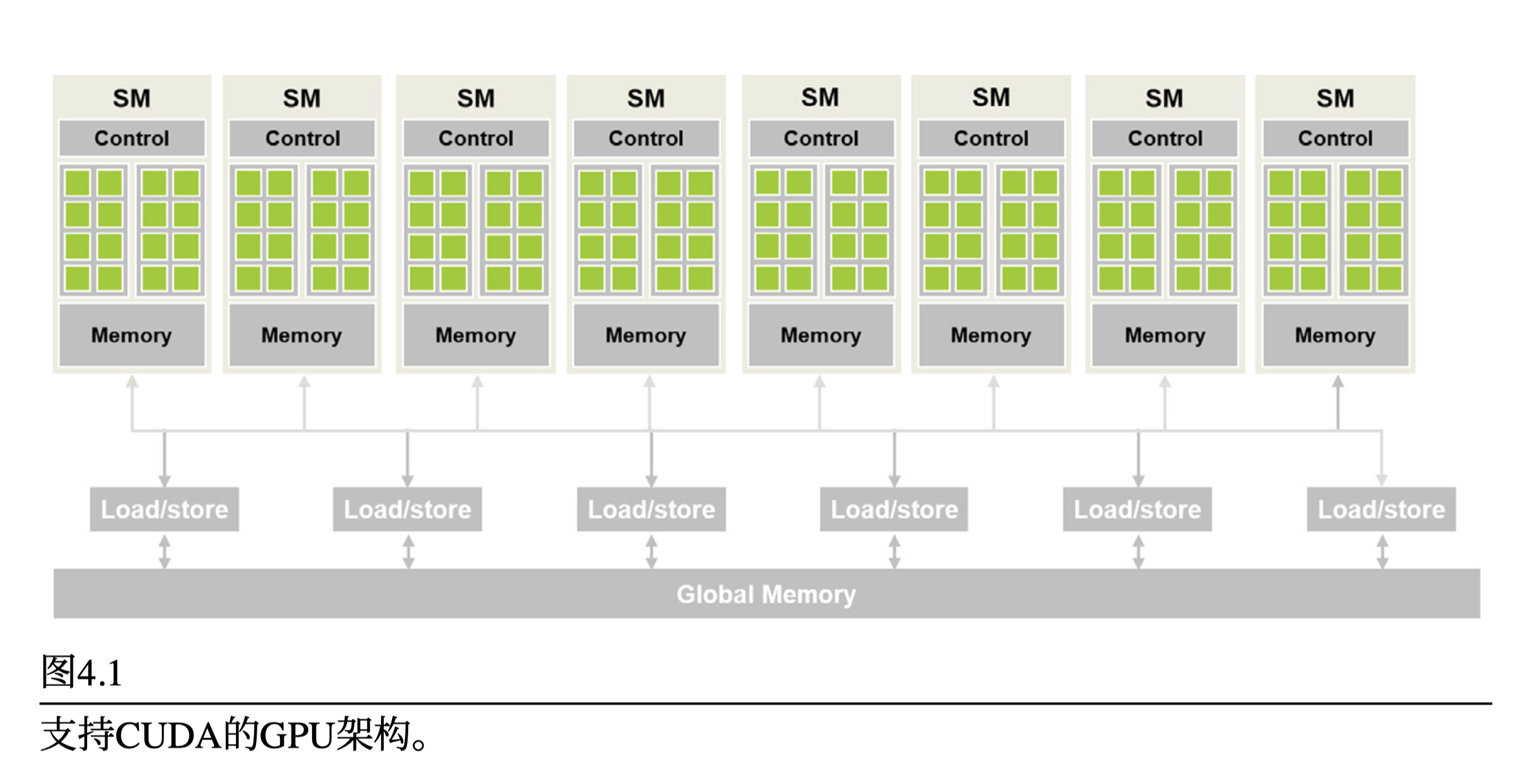
- SM(Streaming Multiprocessor,流式多处理器)内的绿色小方块是cuda核心(流式处理器),cuda核心组织成SM分区(图中8个一组的绿色小方块)
- 全局内存是片外内存,通常是HBM(高带宽内存)
 多个线程块可以分配给一个SM
多个线程块可以分配给一个SM
同一线程块中的线程共享SM内存。
屏障同步
同一线程块中的线程用__syncthreads()作屏障同步。
两个__syncthreads()是两个不同的屏障,同一块中的线程要到达同一屏障。
void incorrect_barrier_example(int n) {
...
if (threadIdx.× % 2 == 0) {
...
__syncthreads();
} else {
...
__syncthreads();
}
}不同块中的线程不能作屏障同步。 这使得CUDA能够以任意顺序执行块,因为它们不需要等待彼此。
线程束 (warp)
线程块进一步分为线程束。线程束的大小为32,因此线程块的大小为32的倍数。
全局的块调度器为SM分配一个线程块。
线程块分为线程束,SM的线程束调度器为SM分区分配一个线程束来执行。假设SM分区的核心数为8,线程束需要 32线程/8核心=4周期 来执行。线程束中的32个线程遵循 SIMD 模型,执行相同的指令、操作不同的数据。
 图:grid - block - warp - thread
ref
图:grid - block - warp - thread
ref
warp发散:当warp内的线程遵循不同的控制流路径时,SIMD硬件将对每条路径遍历一次。例如,对于if-else结构,当warp内的某些线程执行if路径、某些线程执行else路径,硬件将遍历两次。一次遍历执行遵循if路径的线程,另一次遍历执行遵循else路径的线程。在每次遍历期间,遵循另一路径的线程不允许生效。从Volta架构开始,这些过程可以并发执行,即一个过程的执行可能与另一个过程的执行交错进行。
零开销调度:SM在硬件寄存器中保存分配给warp的所有执行状态,因此切换warp时无需保存和恢复状态
5
计算强度:计算与全局内存访问的比率,FLOP/B
 Roofline模型,左侧是内存带宽受限,右侧是计算受限
Roofline模型,左侧是内存带宽受限,右侧是计算受限
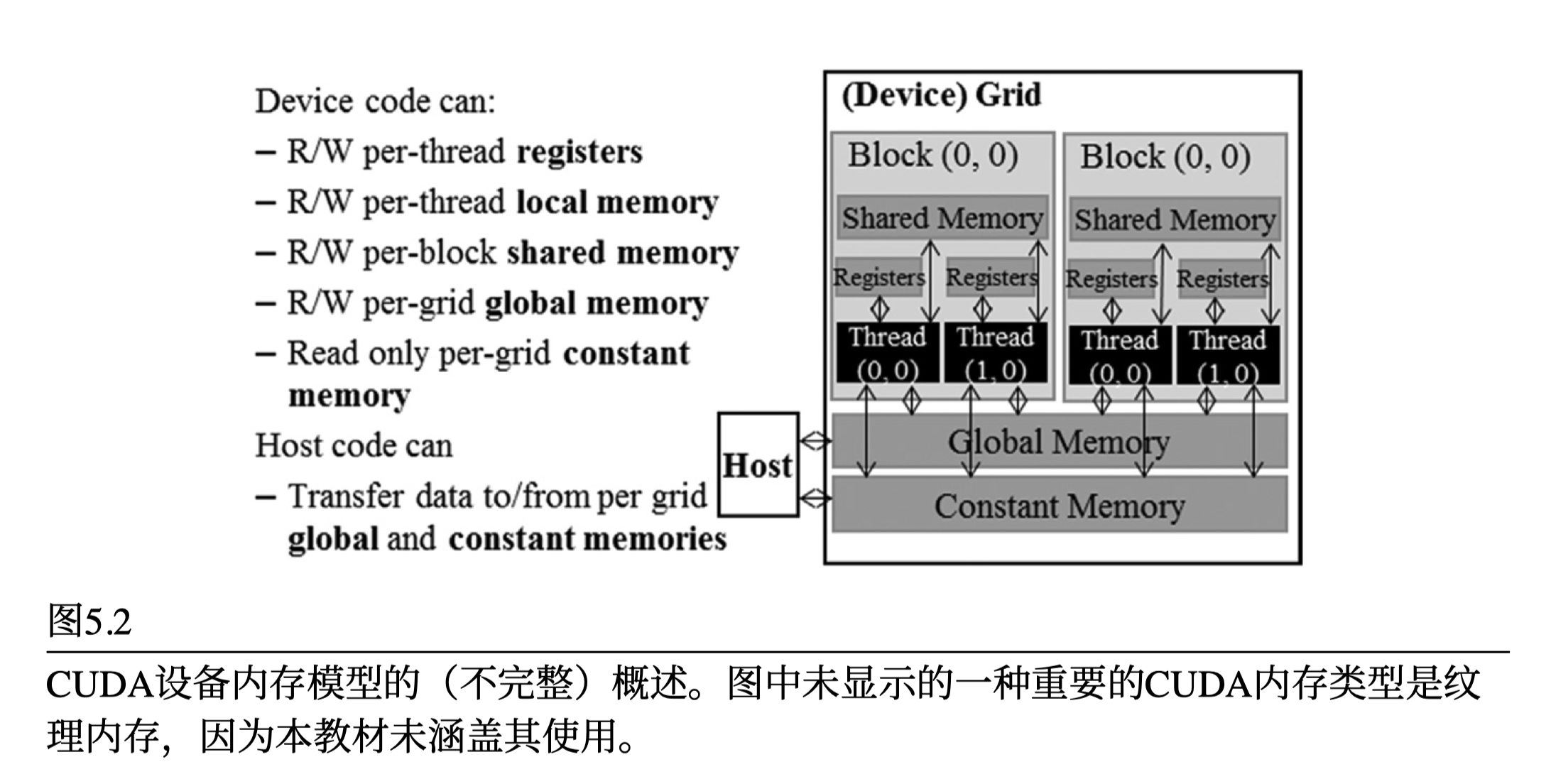
- local memory:使用 Global Memory 保存线程私有数据,因此是片外内存
- Shared Memory:分配给线程块,片上内存
- SM分区的寄存器文件中保存所有调度到该SM分区的线程的寄存器
矩阵乘法的分片计算

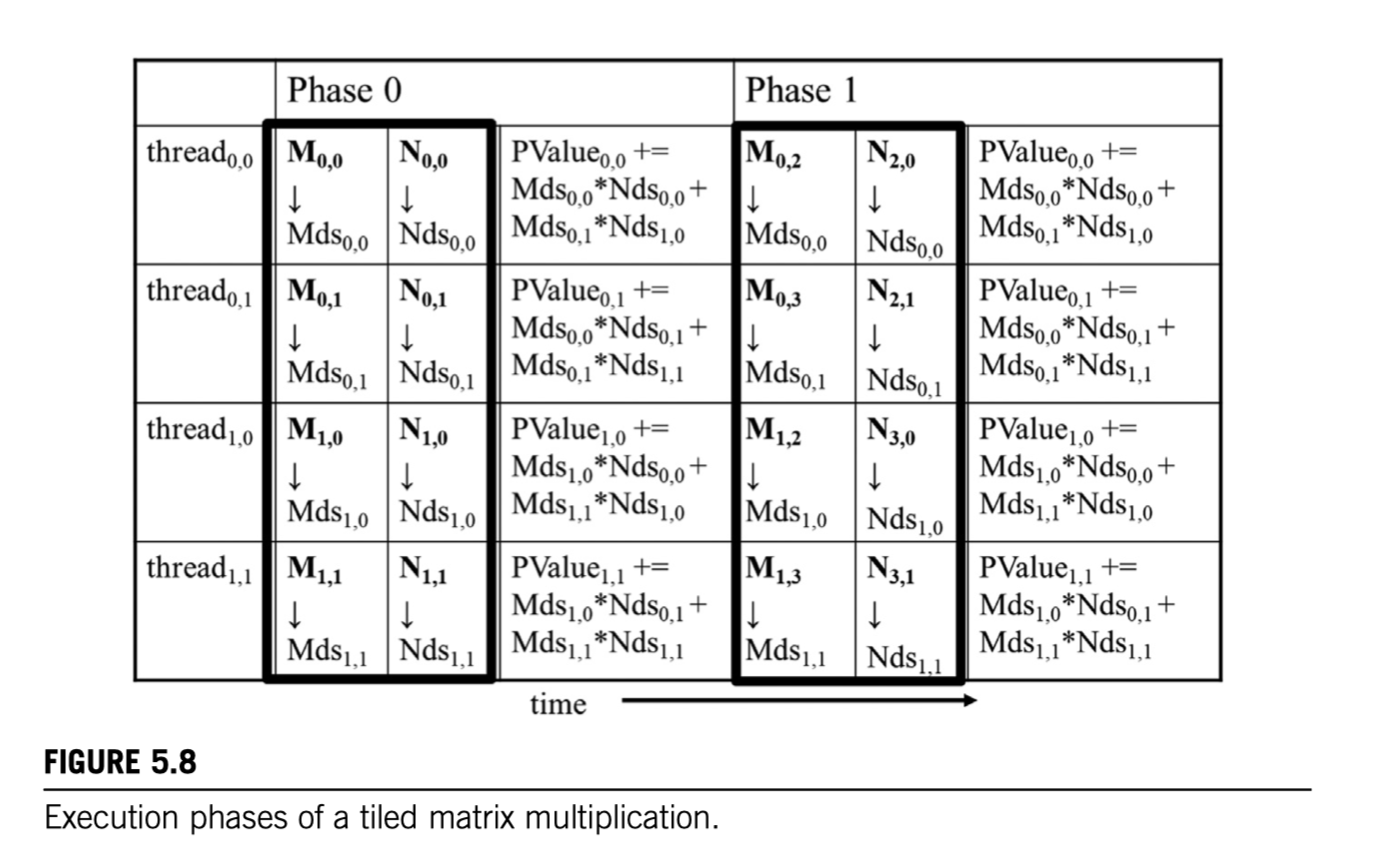
对 M、N 分片,决定了P分片,P分片内每个元素一个线程。对P分片分阶段计算。每个阶段由分片内的所有线程互相配合将M、N的对应分片加载到共享内存(每个线程将一个M元素、一个N元素加载到共享内存),然后利用共享内存计算。假设分片的维度为WIDTH,可以将全局内存访问量减少为1/WIDTH。
6
DRAM burst:一种数据传输模式,允许在单个地址请求后,连续读写多个相邻存储单元的数据。
内存合并(Memory Coalescing):当线程束中的线程同时访问连续的全局内存位置时,硬件会将这些访问合并为对连续DRAM位置的统一访问。
 DRAM系统的并行结构:通道和存储体
DRAM系统的并行结构:通道和存储体
 存储体bank的空闲时间是 DRAM单元阵列访问延迟
存储体bank的空闲时间是 DRAM单元阵列访问延迟
如果存储阵列访问延迟与数据传输时间的比率为R,为充分利用通道总线的数据传输带宽,就需要至少 R+1 个存储体。
 交错数据分布:先沿 channel 再沿 bank
交错数据分布:先沿 channel 再沿 bank
7
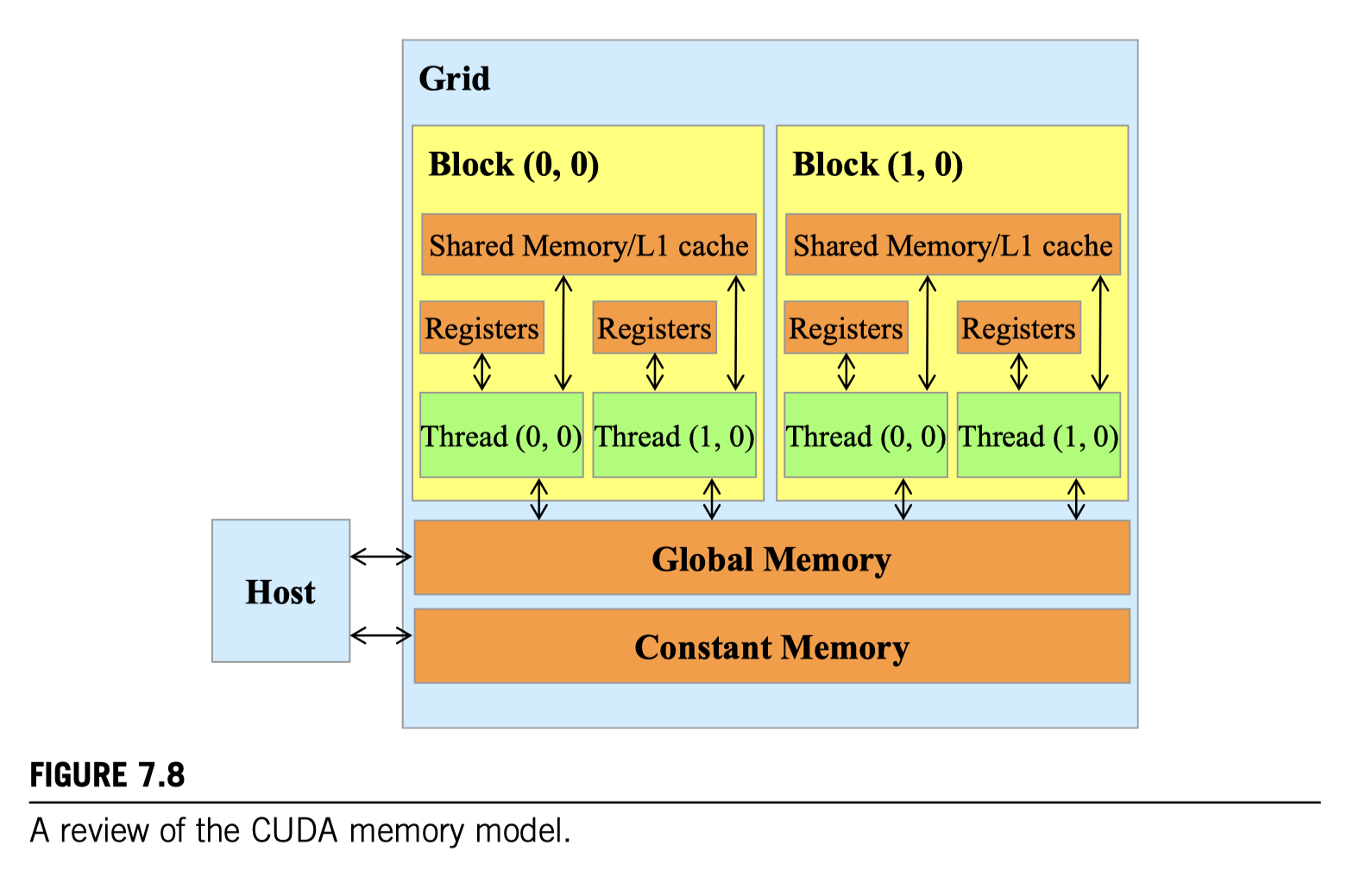
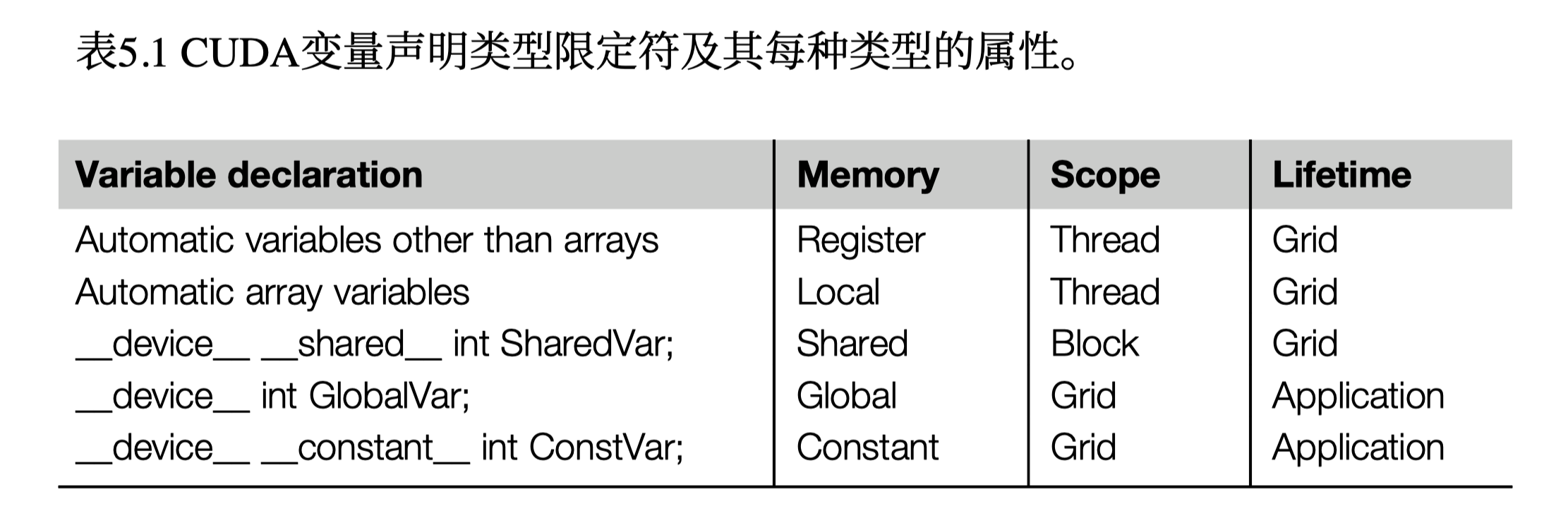
CUDA C允许程序员声明变量驻留在常量内存中。与全局内存变量一样,常量内存变量对所有线程块都是可见的。主要区别在于,常量内存变量的值在内核执行期间不能被线程修改。此外,常量内存的大小相当小,目前为64 KB。
与CUDA共享内存或一般的暂存存储器不同,缓存对程序是“透明”的。也就是说,要使用CUDA共享内存来保存全局变量的值,程序需要将变量声明为__shared__,并显式地将全局内存变量的值复制到共享内存变量中。另一方面,在使用缓存时,程序只需访问原始的全局内存变量。处理器硬件会自动将最近或最常使用的变量保留在缓存中,并记住它们的原始全局内存地址。当以后使用其中一个保留的变量时,硬件会从它们的地址中检测到该变量的副本在缓存中可用。然后,变量的值将从缓存中提供,从而消除了访问DRAM的需要。
参考
- 《大规模并行处理器编程》