#AI#paper#image
Swin: Shifted window
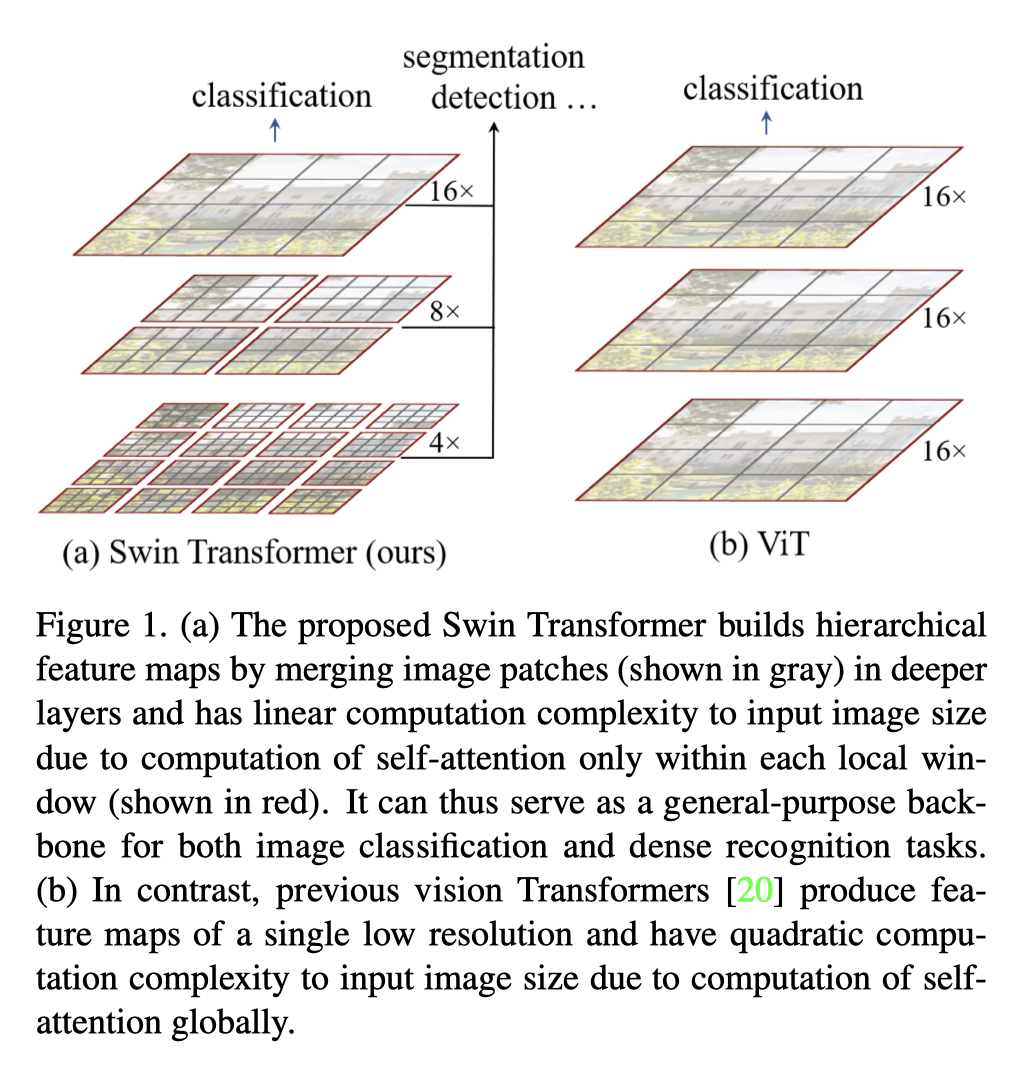
- 4x, 8x, 16x:各stage的下采样倍率
- 在红色窗口算自注意力
 架构图
架构图
4x:对应Linear Embedding,代码可用卷积操作(核4x4、步长4)
8x, 16x, 32x:Patch Merging。先像素重组:每2x2个相邻的特征点作为一组,取每组相同位置的点构成特征图,这4张特征图在通道维度上叠起来。再用1x1卷积将通道数减半。

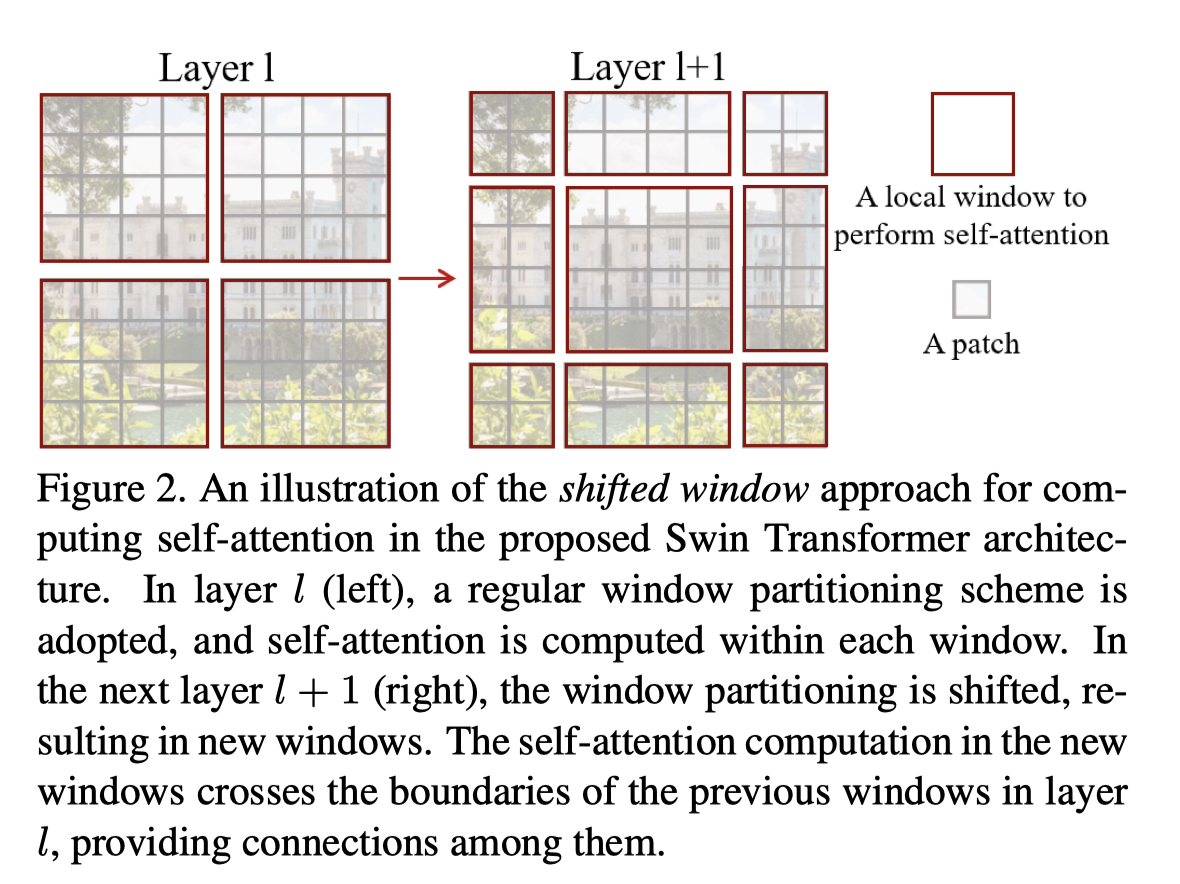
图b的Swin块:先算窗口(W)的多头自注意力(MSA),再算移位窗口(SW)的MSA
移位窗口(Shifted Window)
向右下角移动(win_len/2, win_len/2)个patch
高效计算SW-MSA:循环移位+掩码
 把左边和上方多出来的部分,直接拼到右边和下方去。
9个大小不一的窗口 => 4个大小相同的窗口,窗口内用掩码让拼在一起的部分不能互相看。
具体说来:
把左边和上方多出来的部分,直接拼到右边和下方去。
9个大小不一的窗口 => 4个大小相同的窗口,窗口内用掩码让拼在一起的部分不能互相看。
具体说来:
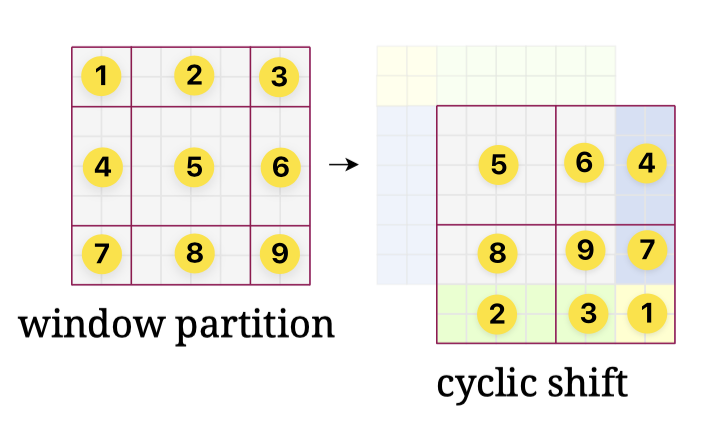
- 左上窗口:只有区域5,不需要掩码
- 右上窗口:区域6和区域4的像素不能互相看
- 左下窗口:区域8和区域2的像素不能互相看
- 右下窗口:4个区域的像素都不能互相看
假设窗口大小为(i,j)的掩码值为-100。掩码矩阵将加到