DSA:Deepseek Sparse Attention 解决长上下文时,计算量和显存占用与长度平方成正比的问题。
将注意力的复杂度从
闪电索引器
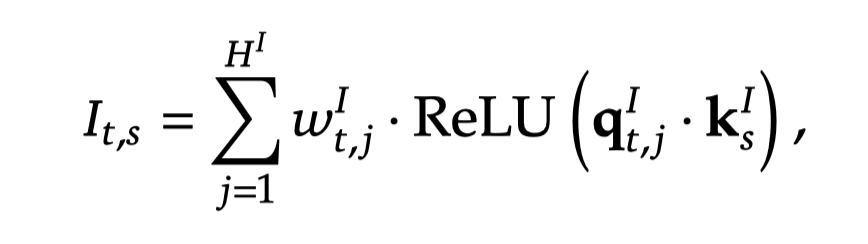
:当前 token t对历史token s的关注度:索引器的头数,每个头负责寻找不同的特征 : 头j的权重:当前 token t的低维量化:历史 token s的低维量化
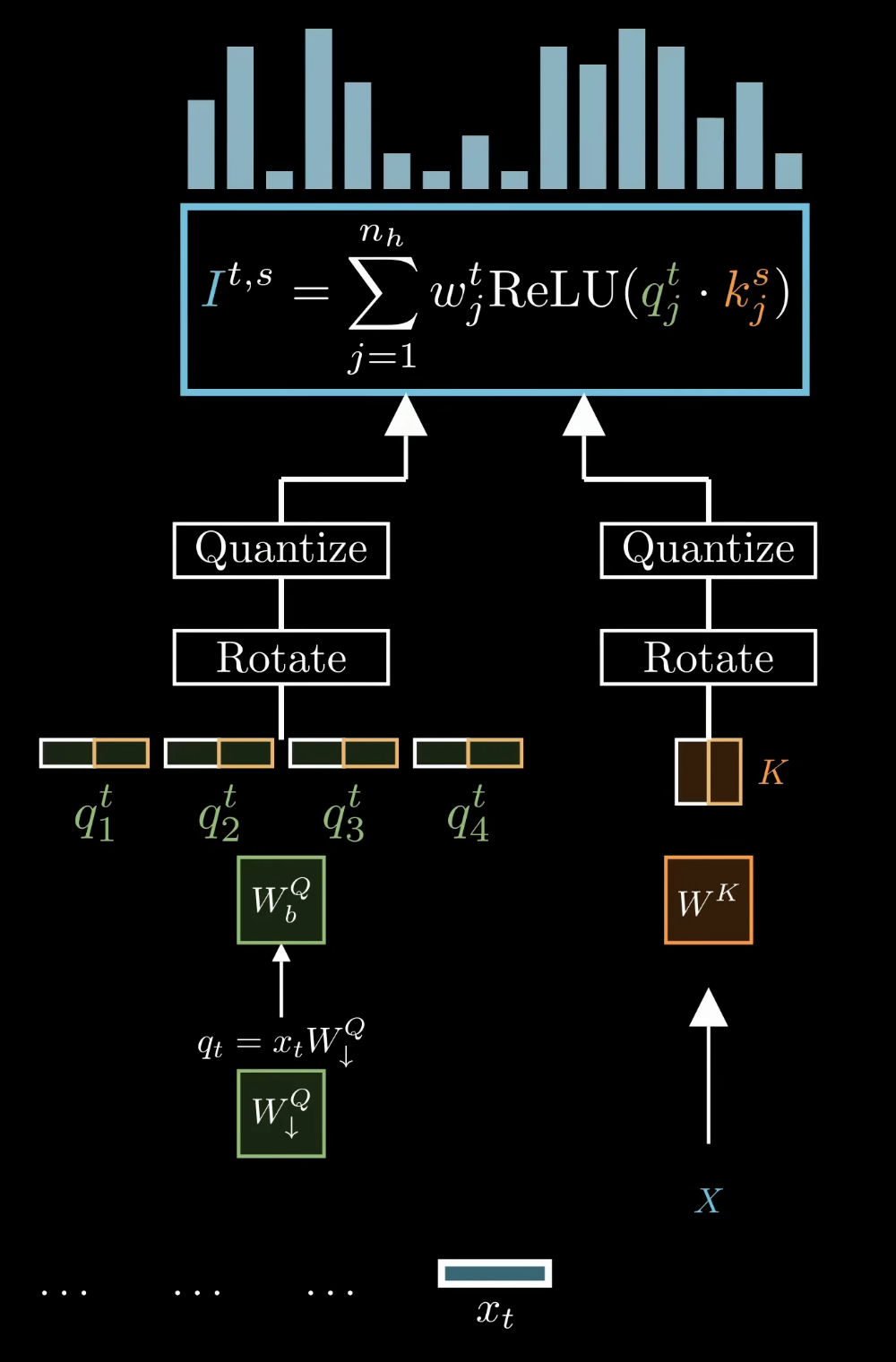
- 量化+ReLU,保证了快速计算。
- 在量化前施加旋转(FWHT,Fast Walsh-Hadamard Transform),让离群值分散到各坐标。 ref
选择top-k
算完
 将数据从流式多处理器SM片外的全局内存 —搬进-> SM片上的共享内存
将数据从流式多处理器SM片外的全局内存 —搬进-> SM片上的共享内存